Hands On : LogStash, ElasticSearch, Kibana, et plus encore
Explication de quelques concepts spécifiques à ElasticSearch.
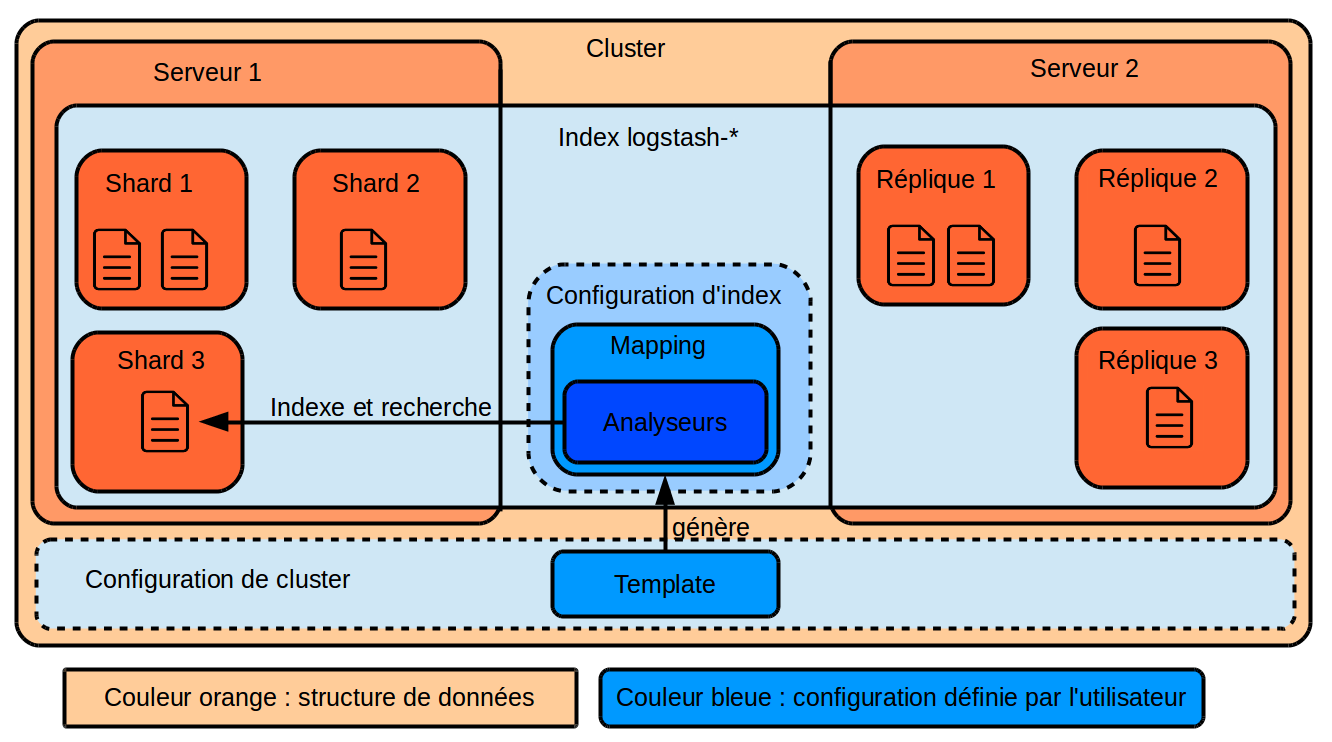
Stockage interne des données
Index
Un index est une sorte de répertoire dans lequel ElasticSearch va stocker des documents. Lorsqu'on demande d'indexer des données, il faut indiquer dans quel index il faut les placer. Lorsqu'on fait des recherches, on peut préciser un index ou un ensemble d'index sur lesquels exécuter la requête.
Dans notre cas, LogStash a décidé du nom de l'index à notre place en indiquant à ElasticSearch le nom d'index commençant par logstash- et terminant par le jour du log à indexer.
Document
Un document désigne une donnée indexée dans ElasticSearch. Cette donnée a un type qui défini les champs qu'elle contient et la manière dont il est indexé. Lorsqu'on fait une recherche dans ElasticSearch, chaque résultat retourné par la recherche est un document.
Dans notre cas, un document est donc une ligne de logs Apache.
Shards
Un shard est une portion d'index, qui contient des données.
Lorsqu'il reçoit des documents à indexer dans un index donné, ElasticSearch les dispatche de manière homogène entre différents shards. Par défaut, chaque index possède 5 shards mais il est possible de configurer cette valeur en fonction du nombre de nœuds dans le cluster ElasticSearch, de la volumétrie de données et des requêtes réalisées. Chaque shard porte donc une partie des données de l'index, 20% dans notre cas puisque l'index possède 5 shards. Ce sont ces shards qu'ElasticSearch va ensuite automatiquement répartir entre les nœuds du cluster, ainsi que leurs répliques (1 par défaut) pour assurer à la fois la scalabilité, les performances, et la tolérance aux pannes.
Mappings et templates
Un mapping est, dans un index, la description de la structure des données et pour chaque champ, de la manière dont il va être indexé. Le mapping peut ainsi indiquer qu'un champ texte devra être analysé en séparant chaque mot selon un caractère de séparation (un espace généralement, mais il peut également s'agir d'une virgule, ou d'un |), et en le passant en minuscules. Ainsi, dans cet exemple, si un champ myfield contient la valeur Un|DEUX|trois et qu'on indexe en séparant sur les | et en minuscules, les valeurs un, deux et trois vont être indexées séparément comme correspondant au champ myfield de ce document.
Un template est une configuration globale du cluster ElasticSearch, qui va être traduite en mappings lors de la création des index si leur nom correspond au pattern indiqué dans le template. Comme on l'a vu, les index peuvent être créés dynamiquement au fil du temps, cela permet donc de configurer une fois l'indexation et que cela s'applique automatiquement aux nouveaux index.
Récapitulatif des relations entre concepts
Explication du résultat d'une requête
Dans le cadre de ce tutorial, après avoir injecté un document dans ElasticSearch via LogStash, nous pouvons récupérer ce document en faisant une recherche sans aucun critère sur l'index logstash-2015.01.04. Cela se fait en entrant dans un navigateur l'URL suivante : http://localhost:9200/logstash-2015.01.04/_search. Le résultat devrait être (une fois mis en forme) :
{
"took":226,
"timed_out":false,
"_shards":{"total":5,"successful":5,"failed":0},
"hits":{
"total":1,
"max_score":1.0,
"hits":[
{
"_index":"logstash-2015.01.04",
"_type":"logs",
"_id":"AVF4U1CkEZ3y1kCGmOik",
"_score":1.0,
"_source":{
"message":"83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"@version":"1",
"@timestamp":"2015-01-04T05:13:42.000Z",
"host":"claire-i5",
"path":"/home/claire/Documents/atelier_es_mydir/logstash-tutorial-small.log",
"clientip":"83.149.9.216",
"ident":"-",
"auth":"-",
"timestamp":"04/Jan/2015:05:13:42 +0000",
"verb":"GET",
"request":"/presentations/logstash-monitorama-2013/images/kibana-search.png",
"httpversion":"1.1",
"response":"200",
"bytes":"203023",
"referrer":"\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"",
"agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\""
}
}
]
}
}
Le début indique que la requête a pris 226ms et qu'elle n'a pas déclenché de timeout :
"took":226, "timed_out":false,
La suite indique que la requête a été faite sur 5 shards et qu'aucun d'eux n'a déclenché d'erreur.
"_shards":{"total":5,"successful":5,"failed":0},
Enfin, viennent les hits, donc les documents qui correspondaient à la recherche effectuée. Dans notre cas, nous n'avons précisé aucun critère donc la totalité des documents (1) a été retournée.
On retrouve ainsi le nombre total de résultats (1), et le max_score qui indique à quel point le document considéré comme le plus pertinent par rapport à la recherche, est pertinent.
"total":1, "max_score":1.0,Le fonctionnement du scoring est assez complexe, nous n'allons donc pas nous attarder dessus dans ce tutoriel. Il faut cependant savoir que c'est le critère de tri par défaut des résultats (du plus pertinent au moins pertinent). Cela étant assez peu intéressant pour consulter des logs (que nous préférons généralement triés par date, même quand nous cherchons une chaîne de caractères précise par exemple), nous préciserons donc souvent un autre critère de tri, notamment sur le champ
@timestamp vu précédemment.
Viennent ensuite les résultats eux-même. Dans notre exemple, nous retrouvons bien la ligne de log découpée en champs nommés vue à l'étape 1. Un hit contient, en plus du contenu du document (la ligne de log) stocké dans le champ _source, d'autres champs correspondant à des metadata ajoutées ou calculées par ElasticSearch.
"_index":"logstash-2015.01.04", "_type":"logs", "_id":"AVF4U1CkEZ3y1kCGmOik", "_score":1.0,On y retrouve le nom de l'index dans le champ
_index, et le score par rapport à la recherche dans _score. Le champ _id contient quant à lui l'identifiant unique du document dans l'index, ce qui permet d'y accéder ensuite directement. Il peut être imposé par le client lors de l'envoi des documents à indexer, ou plus fréquemment il n'est pas précisé et comme ici ElasticSearch le génère.
Enfin, on trouve le champ _type, positionné à la valeur logs. Ici encore, LogStash nous a mâché le travail et à indiqué à ElasticSearch que le document qu'il lui envoyait était de type logs. Cela a une grande importance, car c'est sur ce type qu'ElasticSearch va se baser pour savoir quels champs il peut s'attendre à trouver dans le document, et comment il va devoir les indexer : chaînes de caractères ? entiers ? date ? indexés en texte brut ou découpés selon des caractères de séparation ? etc.



